 Cameron MacLeod
Cameron MacLeod
Disappearing documentation (a Kubernetes war story)
Sun 03 May 2020 BloggingI like a good war story, and I like them even more when I get to tell them. While writing my dissertation, I ran into a case of disappearing documentation. Here's what happened.
As part of my undergraduate dissertation, I was working with Kubernetes, and more specifically, the controllers within Kubernetes. A controller can be thought of as a generalised thermostat. Just as a thermostat maintains temperature in a house, a controller maintains state in a cluster.
A controller has some desired state, some world state, and a way of affecting the world state (an actuator). In the example of the thermostat, the world state would be the current temperature, the desired state would be the user-set temperature, and the actuator would be a heating system.
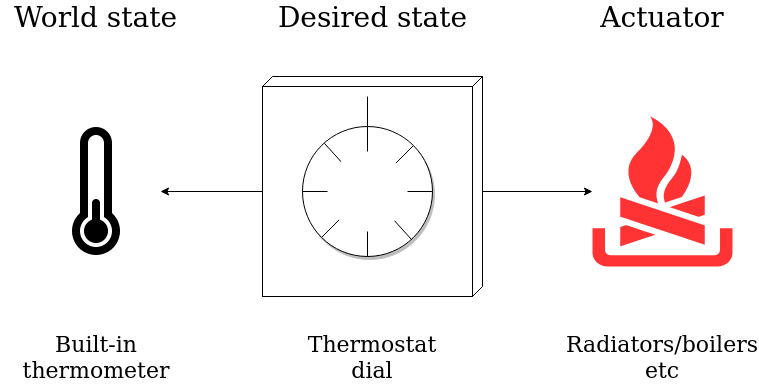
Kubernetes has lots of controllers, but the one relevant for this story is the Horizontal Pod Autoscaler. Its job is to check the average CPU used by a set of pods. If the usage is higher or lower than the target usage, then it will create new pods or delete them appropriately. A pod in Kubernetes is a 'logical host', the equivalent of a virtual machine.
Controllers in Kubernetes are implemented as control loops. This means that every N seconds they will collect information about the state of the world, act on it if necessary and then go back to sleep for the next N seconds.
For this part of my dissertation, I needed to measure the time it takes for each iteration of the autoscaler control loop to run. This was to test whether it was correlated with the load on the Kubernetes cluster, something that an attacker may be interested in. The loop execution time, in theory, should be influenced by how much work the autoscaler (and, more generally, the master node) is doing.
I planned to do this from within the cluster, and the flow roughly went as follows:
- Record the startup time of a worker pod.
- That pod busy loops with high CPU usage.
- A short while later, the first iteration of the autoscaler loop runs and decides that more pods need to be scheduled.
- A new worker pod is brought up and the startup time recorded.
- The two worker pods busy loop with low CPU usage.
- The autoscaler runs again but this time decides it needs to destroy a pod.
- A worker pod receives SIGTERM and records the time.
- The process starts again.
The time between the startups and terminations of the nodes (in bold above) should be correlated with how long it takes the autoscaler control loop to run. However, a problem with this flow is that the controller has a stabilization window to prevent pods from being created and deleted too often. The window ensures that after making a change, Kubernetes won't make another change until the stabilization window has expired. Luckily this can be set, and this is where the disappearing documentation comes in.
The documentation for the Horizontal Pod Autoscaler (HPA) contains a section on the stabilization window above, which included the following text at the time I was looking at it:
Starting from v1.17 the downscale stabilization window can be set on a per-HPA basis by setting the
behavior.scaleDown.stabilizationWindowSecondsfield in the v2beta2 API. See Support for configurable scaling behavior.
This was what I was looking for, so I set this field in my HPA deployment file and... got an error. I double and triple checked the code I was using to make sure it matched the spec on that page, but every time I tried to kubectl apply this file, I got the error below.
$ kubectl create -f some-autoscale.yaml
error validating "some-autoscale.yaml": error validating data: ValidationError(HorizontalPodAutoscaler.spec): unknown field "behavior" in io.k8s.api.autoscaling.v2beta2.HorizontalPodAutoscalerSpec
Just to make this even more confusing, the Kubernetes API docs agreed with the error that the behavior field didn't exist. At this point, I had exhausted all other options and had to turn to StackOverflow for help. At 7PM I posted a question, Kubernetes unknown field "behavior", and at 11PM I received an answer. The answerer said that I was reading the docs wrong and that the field didn't exist in the first place. Ready to drag this unsuspecting samaritan into my confusion, I went to sleep and planned to reply the following day.
When I checked the docs the following day, the quote from above was missing. After considering whether I'd imagined it all, I discovered that the Kubernetes docs were in a public GitHub repository that was linked from the bottom of each page. It turned out that a couple of hours before I had posted my question, the text about the behavior object had been removed in a PR. The behavior object was meant to be introduced in V1.18 instead of V1.17 that was current at the time. The reason I hadn't seen the updated docs was probably due to my browser caching the old version since I'd visited that page a lot.
Finding out that I wasn't imagining things and that the docs were wrong was very satisfying. Everything had fallen nicely into place. I answered the Stack Overflow question with a shortened version of this story and carried on with my dissertation.
Now that 1.18 is out, this will no longer be a problem, but I thought it would be an interesting story to share. This was only a small part of my dissertation, which was on mobile networks and Kubernetes. It's now finished (exhausted hooray). If you're interested, you can read it here.